At the time of the Wuhan virus pandemic, everything went online. So seminars become webinars. The other day I am watching somebody presenting online. The deck is useful but the speech is boring. I did a screen capture video on the slide screen for an hour (on mac, so the video is QuickTime format) and I want to reproduce the slides from the video. This is what I did.
It is a blessing to do the screen capture on mac because it is built-in.
⌘-Shift-5 will give you all tools you need to capture a specific retangular
region into video. Otherwise we can do the croping in iMovie or other tools.
Assume we have no issue of croping. The next I want to do is to extract the
pictures from the video, frame by frame. ffmpeg can help and in Python, the
module pyav is the interface:
import av
MOVIE = "screen.mov"
container = av.open(MOVIE)
container.seek(0)
for frame in container.decode(video=0):
seconds = frame.time
picture = frame.to_ndarray(format="rgb")
This is how we get the timing (in float) of each frame and extract the picture as RGB tensor. We can save all frames as pictures but we can do better. Firstly, we do not need to save 24 frames per second (if PAL is used, for example). Indeed, we want to capture a frame only if there is a significant change, correspond to a new slide on the screen. But telling whether the screen is showing a new slide is not trivial because the video is lossily compressed. So it is always never an exact match even the screen seemingly showing the same thing.
After some trial and error, this is what I found:
- Do not use RGB, grayscale is enough. In fact, a one-bit pixel is what we should do eventually because this can keep the signal and erase the compression noise.
- For performance reason, we can assume each slide is showing on screen no less than a few seconds and we sample the video once every, say, 2 seconds and extract slides among them. This is very useful in case of the presenter is moving the mouse cursor on the slides as it can avoid producing slides for very tiny cursor movements
- To tell if one frame and another frame are the same, we can make up a penalty score function to quantify the total pixel difference
So here is the code:
import os
import subprocess
import numpy as np
import pandas as pd
import av
def genweights(frame: np.ndarray) -> np.ndarray:
"""Create a meshgrid for weights as exp(-z^2)"""
ymax, xmax = frame.shape
normfactor = ymax // 2
# y is -1 to 1; x is in same scale but only on rightmost 2/3
y = np.linspace(-ymax//2, ymax-ymax//2, ymax) / normfactor
x = np.linspace(-xmax*2//3, xmax-xmax*2//3, xmax) / normfactor
xx, yy = np.meshgrid(x, y)
weights = np.exp(-(xx**2 + yy**2))
weights[:, :xmax//3] = 0 # left one-third = ignore
return weights
def penalty(prev, this, weight) -> np.ndarray:
"""Compute the pixel-based penalty of two different images"""
this = np.square(this > 128) # convert grayscale into B&W
prev = np.square(prev > 128)
return np.square(this - prev) * weights
MOVIE = "screen.mov" # movie file to read by av.open()
next_t = 2 # time to capture next frame
incr = 2 # time increment per frame capture
prev = weight = None # variables to hold a frame/frame mask
threshold = 1e-3 # score threshold for saving the frame
files = []
container = av.open(MOVIE)
container.seek(0)
for frame in container.decode(video=0):
if frame.is_corrupt or frame.time < next_t:
continue
next_t += incr
# Extract
this = frame.to_ndarray(format="gray")
if prev is None:
# initialization for comparison, and skip this frame
weights = genweights(this) # reusable weight matrix
prev = np.zeros_like(this)
continue
# Compare and save frame as JPEG image
score = np.mean(penalty(prev, this, weights))
prev = this
if score > threshold:
filename = "screen-{:02.0f}m{:.0f}s.jpg".format(frame.time//60, frame.time%60)
files.append(filename)
frame.to_image().save(filename)
# convert image into PDF and remove temp files
subprocess.run(["convert"]+files+["deck.pdf"])
for f in files:
os.unlink(f)
The workflow is simple: Extract frames from the video, save as JPEG, and combine the image files into a single PDF file after finishing the video. The tricky part is how to determine which frame to save.
Given we have two frames in grayscale, a trivial way to compare is to do a diff on each pixel value. Lossy compression means the diff will not be zero almost surely. But we we can take the average diff across all pixels as a metric of how alike are two frames. Moreoever, we can focus on the centre area of the frame because there is where the main content of each slide located. If pixels are changing in other area, it is more likely noise. Combining these two ideas,
- I made the function
genweights(), to weigh each pixel differently. Focusing on the center, where the main content of a slide supposed to be and decay exponentially to the edge (the code above is tailor made for the slides in concern because the left 1/3 of them is the decoration on the slide template) - Create a function
penalty(), which compares two frames (assumed two 2D numpy arrays of grayscale pixel values 0-255). We take the pixel-by-pixel difference between the two frames and scale it to [-1, +1], then take square value on each pixel so we make bigger difference more significant than a small grayscale difference. Afterwards, multiply with the pixel weight and return the result as another 2D array. But in fact, the performance is found to be better if the pixel is B&W, so in the code I make it boolean and square it (so it becomes floating point 0 or 1) – the less information the more accurate it would be.
Once we combine this and take the mean pixel difference score (the line of code
np.mean(penalty(prev, this, weights)) we can empirically find the score
compare to the previously sampled frame as a time series:
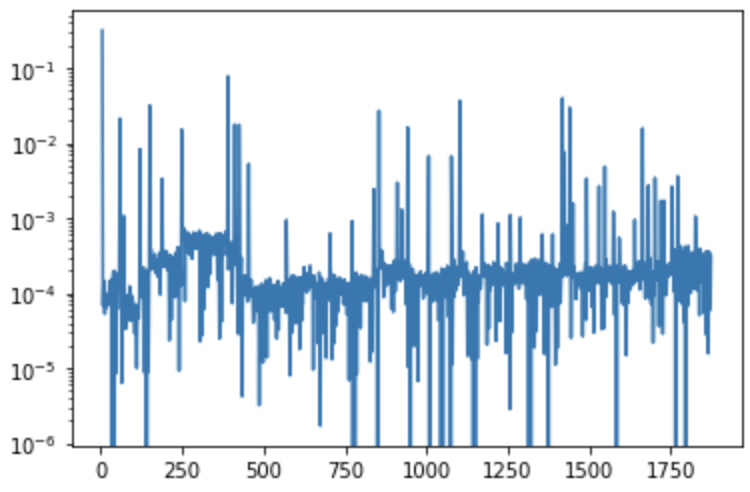
So empirically we find the threshold of 1e-3 seems to be a good one to pick up all those “spikes”. If not empirically, we can run the video twice so we determine the threshold on the first pass (e.g., by interquatile average or moving average) and use it to extract frames on the second pass.