This is the paper that introduced the Vision Transformer (ViT), which proposed that transformers can be used for image classification replacing CNNs. Inspired by the success of transformer models in NLP, this paper explored the technique of using transformers to process 2D image data. The goal is to create a base model that can be adapted for various downstream tasks, just like what transformer models such as BERT (Devlin et al, 2019) did in NLP.
Some prior work explored how to apply self-attention to images, such as Hu et al (2019), Ramachandran et al (2019), and Zhao et al (2020), where MHA blocks are used to replace the convolutional layers. The challenge of applying attention to images is lack of inductive bias that is built into CNNs, such as translation equivariance and locality. But the paper found that it can be overcome by training on more data, such as using the public ImageNet-21K dataset or the in-house JFT-300M dataset, rather than the smaller ImageNet dataset used in ResNet (He et al, 2016).
Architecture
The architecture of ViT is shown in Figure 1 of the paper:
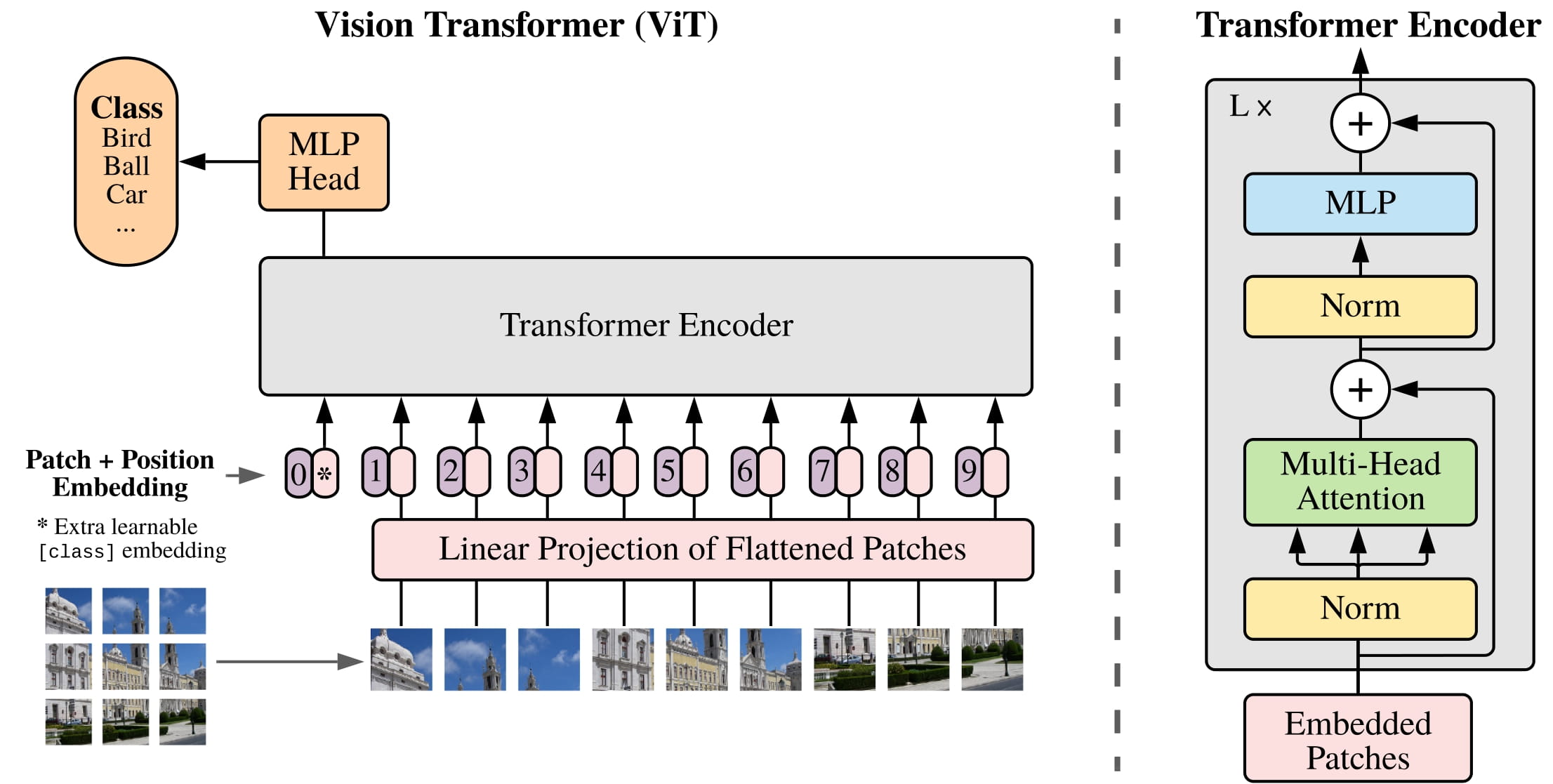
It is a standard transformer model that receives input as a sequence of embedding vectors in dimension $D$, and produce a sequence of hidden state vectors of the same dimension. An image is a tensor of pixel values of shape $(H,W,C)$, which inherently has 2D spatial structure. The model requires a preprocessing step to convert an image from $\mathbb{R}^{H\times W\times C}$ into a flattened sequence of patches in $\mathbb{R}^{N\times(P^2C)}$, where $N=HW/P^2$ is the number of patches, $P$ is the patch size, and $C$ is the number of channels.
Images are split into patches of fixed size $P\times P$, hence each element of the flattened patch sequence is a vector of in $\mathbb{R}^{P^2C}$. Each element is then linearly projected into $\mathbb{R}^D$ as input to the model. The sequence length corresponds to the dimension of the original image.
Similar to BERT’s [cls] token, a classification token is prepended to the input sequence. Its state at the output of transformer will be used for classification through a MLP model. This token is learned, and in the same space as patch embeddings.
The original transformer paper used sinusoidal positional encodings. In ViT, position embeddings are learned. Even the image is 2D, the positional embedding is 1D to correspond to the flattened patch sequence. In training, the input image is scaled to a standard size (224x224 pixels) and during inference, the positional embedding is interpolated if a different image size is used. The paper explored different positional embedding strategies, but found no significant performance gain, hence a simple learned 1D positional embedding is used.
The transformer is encoder-only with pre-norm architecture. Each encoder layer is layer norm-MHA-layer norm-MLP with residual connection around each sublayer. The MLP has 2 layers with GELU activation. In math, the model is defined as:
\[\begin{aligned} E &\in \mathbb{R}^{(P^2C)\times D} & \text{projection matrix} \\ E_\text{pos} &\in \mathbb{R}^{(N+1)\times D} & \text{learned position embedding} \\ \text{MLP}(x) &= \text{GELU}(W_2\cdot \text{GELU}(W_1\cdot x)) & \text{2-layer MLP} \\ z_0 &= [x_\text{class}; x_p^1E; x_p^2E; \dots; x_p^NE] + E_{\text{pos}} \\ z'_\ell &= \text{MHA}(\text{LN}(z_{\ell-1})) + z_{\ell-1} & \ell = 1,\dots,L \\ z_\ell &= \text{MLP}(\text{LN}(z'_\ell)) + z'_\ell \\ y &= \text{LN}(z_L^0) \end{aligned}\]The classification token to prepend to the input sequence is $z_0^0 = x_\text{class}$ and the output is $z_L^0$. Then $z_L^0$ is passed to an MLP as classification head to produce logits.
Note that the patch is the only place that the spatial information is preserved in ViT. And only in the MLP that global perspective can be captured.
The paper also described a “hybrid architecture” where the input is a patch from the feature map output of a CNN instead of raw patches. Embedding projection still applies to the patch to convert the patches into vectors in $\mathbb{R}^D$.
The model is trained on large dataset for classification. To fine-tune the model for a different downstream task, the classification head is removed and a new feedforward layer is added, then retrained on a smaller dataset. In fine-tuning, the patch size is retained, but the sequence length can be changed. The position embedding would be interpolated (considering the 2D location) to fit the new sequence length. This is the only place that 2D structure of the image is manually injected to the ViT.
Evaluation
The paper covered 3 datasets:
- ILSVRC-2012 ImageNet dataset with 1K classes and 1.3M images
- ImageNet-21K with 21K classes and 14M images
- JFT (Sun et al, 2017) with 18K classes and 303M high-res images
and three model variants:
- ViT-Base: 12 layers, D=768, MLP size 3072, 12 heads, 86M params
- ViT-Large: 24 layers, D=1024, MLP size 4096, 16 heads, 307M params
- ViT-Huge: 32 layers, D=1280, MLP size 5120, 16 heads, 632M params
The models were trained on 224x224 pixel images with Adam ($\beta_1=0.9, \beta_2=0.999$) with gradient clipping at global norm 1, batch size 4096, linear learning rate warmup for 10K steps, and then weight decay 0.1. In fine-tuning, SGD with momentum was used and with a reduced batch size of 512.
Depends on the model size, the training varies. For JFT-300M dataset, it is trained for only 7 epochs. For ImageNet-21K dataset, it is trained for 30 or 90 epochs. For ImageNet dataset, it is trained for 300 epochs. The training (ViT-L/16) took 30 days on TPUv3 with 8 cores.
The baseline to compare with is ResNet (He et al, 2016), but with Group Normalization (Wu and He, 2018) and standardized convolutions (Qiao et al, 2019). This is suggested by “Big Transfer (BiT)” (Kolesnikov et al, 2020) that can help transfer learning.
The paper found that ViT-L/16 model (i.e., 16x16 patch size) trained on JFT-300M outperforms alternative architectures. The larger model, ViT-H/14, further improves performance. Note that the smaller the patch size, the longer the sequence length for the same input image. Hence patch size is inversely proportional to the amount of compute.
Variations
The appendices of the paper explored different variations of the model.
The [cls] token approach for image classification is inspired by BERT, but some ResNet model uses global average pooling (GAP) as input to the final classification layer. It is found that GAP performs poorly unless lowering the learning rate from 8e-4 to 3e-4.
The hyperparameters of the transformer model includes the number of layers and the size of the hidden state. The paper found that scaling on depth (number of layers) is more important than scaling on width (hidden state size), but diminishing returns are observed after 16 layers.
Decreasing the patch size and increase the sequence length shows robust improvements on accuracy, but it is computationally more expensive. This also suggests that model size is not a good predictor of performance, but the amount of compute is.
There are multiple ways to encode positional information. 2D positional embedding is simply to set up two sets of embeddings in $\mathbb{R}^{D/2}$ for the $X$ and $Y$ axes, then based on the patch’s position $(x,y)$, concatenate the $X$ and $Y$ position embedding into a final position embedding in $\mathbb{R}^D$.
There are also relative positional embedding (1D case), in which the relative distance between patches are considered to encode the spatial information. This is to apply to query vs key/value that the position difference $p_q-p_k$ is considered. Extra attention is computed, which attends query to the relative positional embedding, and add the result to the main attention between query and key as bias before applying softmax.
The paper found that various ways of positional embedding has no significant difference. Without positional embedding, however, yields the worst performance since that is simply a “bag of patches”.
Instead of attention on a sequence, there are axial attention (Huang et al, 2020 and Ho et al, 2019). That is to perform attention on each axis of the multi-dimensional input tensor independently. Each attention operation mixes information along a particular axis while keeping information along other axes independent. An example is Wang et al (2020), where all 3x3 conv in ResNet50 are replaced by axial self-attention, i.e., row and column attention augmented by relative positional encoding. The paper explored this approach to produce Axial-ViT. It is found to perform better but more costly to compute. It is because each transformer block will be replaced by two axial transformer blocks and an extra MLP is added.
Implementation
The author open-sourced the code on GitHub. Hugging Face also has an implementation of ViT in the transformers library. An example code is as follows:
from transformers import ViTConfig, ViTModel, ViTImageProcessor, ViTForImageClassification
from PIL import Image
import requests
# optional: load the pretrained model
modelid = "google/vit-base-patch16-224"
configuration = ViTConfig() # default config is same as vit-base-patch16-224"
model = ViTModel(configuration) # or ViTModel.from_pretrained(modelid)
# Print model config and architecture
configuration = model.config
print(configuration)
print(model)
# Load and process an image
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained(modelid)
model = ViTForImageClassification.from_pretrained(modelid)
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = outputs.logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
The config and base model architecture can be printed as follows:
ViTConfig {
"_attn_implementation_autoset": true,
"attention_probs_dropout_prob": 0.0,
"encoder_stride": 16,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.0,
"hidden_size": 768,
"image_size": 224,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"model_type": "vit",
"num_attention_heads": 12,
"num_channels": 3,
"num_hidden_layers": 12,
"patch_size": 16,
"qkv_bias": true,
"transformers_version": "4.48.1"
}
ViTModel(
(embeddings): ViTEmbeddings(
(patch_embeddings): ViTPatchEmbeddings(
(projection): Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
)
(dropout): Dropout(p=0.0, inplace=False)
)
(encoder): ViTEncoder(
(layer): ModuleList(
(0-11): 12 x ViTLayer(
(attention): ViTSdpaAttention(
(attention): ViTSdpaSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(output): ViTSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
)
(intermediate): ViTIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): ViTOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(layernorm_before): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(layernorm_after): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
)
)
(layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(pooler): ViTPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
The Hugging Face implementation is at https://github.com/huggingface/transformers/blob/main/src/transformers/models/vit/modeling_vit.py, which is similar to the original but cleaned up. The detail is as follows:
ViTImageProcessorsimply converts the input image to a numpy array, then resize, rescale the pixel to 0-1, normalize and convert into correct format (NHWC or NCHW).ViTForImageClassificationis a wrapper ofViTModeland aLinearlayer- the base model from
ViTModelprocesses the input first, then the first element of the output sequence is extracted and pass on to theLinearlayer to produce the logits - in code:
logits = classifier(sequence_output[: 0, :]), forsequence_outputa tensor of batch size × sequence length × embedding dimension ($N,L,D$)
- the base model from
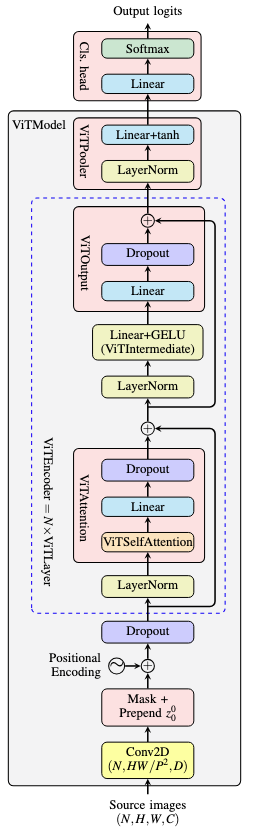
ViTModelis a composition ofViTEmbeddings,ViTEncoder,LayerNorm,ViTPooler, and process the input in this orderViTEmbeddingsdefinedcls_token,mask_token,position_embeddingsas trainable parameters- input is first processed by
ViTPatchEmbeddings, which uses aConv2Dlayer to convert the input into a sequence of patches. This is a trick that sets the kernel size and the stride to the patch size. This is equivalent to extracting patches from the input image. The transform of patch to embedding vector is by setting the number of channels in Conv2D to dimension $D$. The output of Conv2D has shape $(N,D,H/P,W/P)$, then flattened to $(N,D,HW/P^2)$ and transposed to $(N,HW/P^2,D)$. The sequence length is $L=HW/P^2$. - the sequence produced by
ViTPatchEmbeddingsis prepended withcls_token, then optionally substituted the masked positions withmask_token. The position embeddings are then added to the sequence, apply dropout, and set as output.
- input is first processed by
ViTEncoderdeclared multipleViTLayerasnn.ModuleList, and run each layer in tandem- each
ViTLayeris a pre-norm transformer layer: layer norm-attention-layer norm-intermediate-output projection - attention is implemented as
ViTAttention, in which process the input overViTSelfAttentionandViTSelfOutputViTSelfAttentionimplements MHA with projection matrices for query, key, and value.- The input tensor of shape $(N,L,D)$ is projected to shape $(N,L,n_H d)$ for $n_H$ heads and head dimension $d$. $D=n_H d$.
- Then reshaped to $(N, L, n_H, d)$, permuted to $(N, n_H, L, d)$, the compute attention output
- The output is then reshaped to $(N, L, n_H d)$
ViTSelfOutputis a linear layer and a dropout layer, no activation function
- intermediate layer in
ViTIntermediateis a linear layer and a GELU activation function - output projection is in
ViTOutput, which is a linear project and dropout then add the residual connection
- each
- After all encoder layers, a final layer norm is applied, then a
ViTPoolerViTPooleris a linear layer and an activation function, usually the default tanh is used- by default the output size is the same as the hidden size, i.e., just a projection to the same dimension
In picture, the model architecture of ViTForImageClassification is as follows:
References
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In NAACL, 2019.
- Han Hu, Zheng Zhang, Zhenda Xie, and Stephen Lin. Local relation networks for image recognition. In ICCV, 2019.
- Prajit Ramachandran, Niki Parmar, Ashish Vaswani, Irwan Bello, Anselm Levskaya, and Jon Shlens. Stand-alone self-attention in vision models. In NeurIPS, 2019.
- Hengshuang Zhao, Jiaya Jia, and Vladlen Koltun. Exploring self-attention for image recognition. In CVPR, 2020.
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016.
- Chen Sun, Abhinav Shrivastava, Saurabh Singh, and Abhinav Gupta. Revisiting unreasonable effectiveness of data in deep learning era. In ICCV, 2017.
- Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. Big transfer (BiT): General visual representation learning. In ECCV, 2020.
- Yuxin Wu and Kaiming He. Group normalization. In ECCV, 2018.
- Siyuan Qiao, Huiyu Wang, Chenxi Liu, Wei Shen, and Alan Yuille. Weight standardization. arXiv preprint arXiv:1903.10520, 2019.
- Zilong Huang, Xinggang Wang, Yunchao Wei, Lichao Huang, Humphrey Shi, Wenyu Liu, and Thomas S. Huang. Ccnet: Criss-cross attention for semantic segmentation. In ICCV, 2020.
- Jonathan Ho, Nal Kalchbrenner, Dirk Weissenborn, and Tim Salimans. Axial attention in multidimensional transformers. arXiv preprint arXiv:1912.12180, 2019.
Bibliographic data
@inproceedings{
title = "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale",
author = "Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby",
booktitle = "In Proceedings of the 9th International Conference on Learning Representations (ICLR)",
month = "May",
year = "2021",
arxiv = "2010.11929",
url = "https://github.com/google-research/vision_transformer",
}