This is a paper of a new model for object detection, which the output is a bounding box and a class label. Compared to other object detection models, FCOS does not use predefined anchor boxes. This model is described as “anchor box free and proposal free”.
Anchor-based object detection models usually use 3 scales and 3 aspect ratios for each anchor location (pixels). Even with a small image, there are a lot of anchor boxes to start with and most of them will become negative samples.
The architecture of FCOS is illustrated in Fig.2 of the paper, as follows:
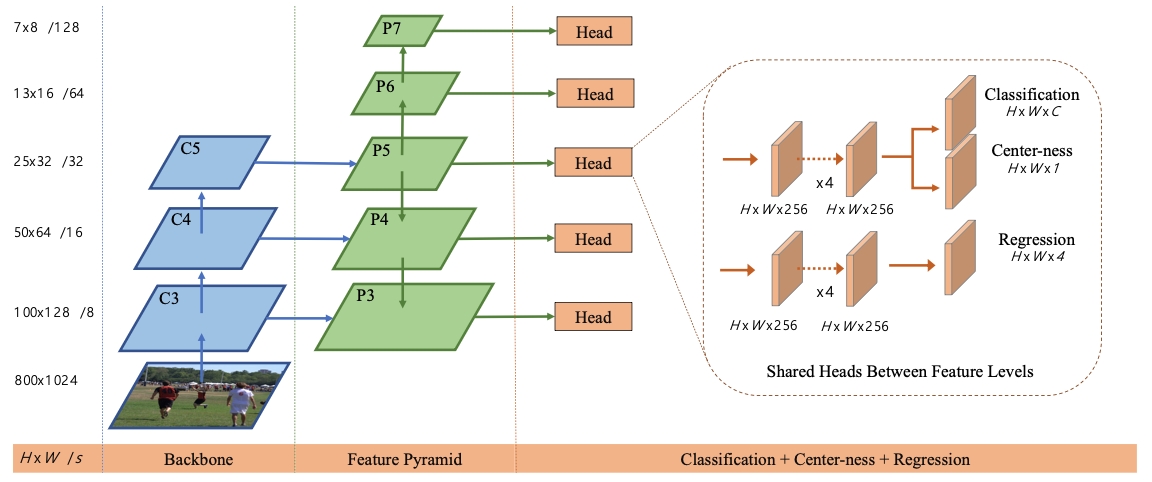
Structure
The FCOS is a fully convolutional network (FCN). The training data is a set of bounding boxes $(x_0, y_0, x_1, y_1)$ and class label $c$. The bounding box is defined as the coordinates of the top-left and bottom-right corners.
In the backbone and the feature pyramid network, every layer produces a feature map $F_i \in \mathbb{R}^{H\times W\times C}$. At each spatial location $(\check{x},\check{y})$ of feature map $F_i$, the corresponding pixel location of the input image is $(\lfloor s/2\rfloor+s\check{x}, \lfloor s/2\rfloor+s\check{y})$, where $s$ is the stride of the feature map and this is the center of the receptive field of the feature map at that location.
In FCOS, the image location $(x,y)$ of a feature map is a positive sample if the corresponding location of the input image is inside the ground truth bounding box (of class $c>0$, which $c=0$ denotes background). Every feature map is responsible for a bounding box of a certain size range. If there are multiple bounding boxes that contain the same pixel, the one with the smallest area is selected.
The output of the FCOS model is from the prediction head. Three branches are in the head: classification, centerness, and bounding box regression.
Training of the FCOS model is to run classification of the class label $c$ and regression of the bounding box offset $(l,t,r,b)$ for each positive sample at image location $(x,y)$. The offset is defined as:
\[\begin{aligned} l &= x - x_0 \\ t &= y - y_0 \\ r &= x_1 - x \\ b &= y_1 - y \end{aligned}\]Note that these offsets should always be positive (otherwise the location is not within the bounding box). The model employs exponential function $\exp(x)$ to enforce this. Centerness is a value between 0 and 1 to indicate how the point $(x,y)$ is located within the bounding box.
Multi-level prediction
Similar to other object detection models, FCOS also uses the feature pyramid network (FPN) to produce multi-level predictions. The model in the paper has a backbone CNN (e.g., ResNet-50) that produces feature maps $C_3,C_4,C_5$. The FPN is constructed as follows:
- $P_3,P_4,P_5$ are produced from $C_3,C_4,C_5$ followed by a $1\times 1$ convolution, hence the FPN layer share the same receptive fields as the corresponding backbone layer
- $P_6$ is produced from $P_5$ followed by a $3\times 3$ convolution and a stride of 2
- $P_7$ is similar to $P_6$, but produced by $P_6$ instead of $P_5$
- Resulting strides of feature maps $P_3,P_4,P_5,P_6,P_7$ w.r.t. input image: 8, 16, 32, 64, 128
Each spatial location of each feature map $P_i$ is used to predict one bounding box and class label. Each feature level is responsible for predicting objects of a certain size range. Note that the $(l,t,r,b)$ defined above is the offset in pixel sizes, then for feature level $P_i$, the prediction is only for the range that:
\[m_{i-1} \le \max(l,t,r,b) < m_i\]and $m_2=0, m_3=64, m_4=128, m_5=256, m_6=512, m_7=\infty$.
The prediction head is illustrated in Fig.2 of the paper. But there is only one head in the model, shared by all levels of the FPN. This design is found to improve the detection quality as well as being parameter efficient.
The regression branch in the prediction head outputs a vector of length 4 for each input location, which is the offset of the bounding box. The branch is built as a 4-layer convolution network, following the RetinaNet (Lin et al, 2017) design.
Since different feature levels supposed to use a different size of bounding box due to the different strides, to make them compatible with the same prediction head, the offsets output will be processed as:
\[\exp(s_ix)\]with a trainable scale $s_i$ for each level $P_i$.
The classification branch outputs a vector of length $C$ (where $C$ is the number of classes), each is a binary classifier instead of a softmax classifier. Also following the RetinaNet design, the classification branch is built as a 4-layer convolution network.
To further improve the detection quality, the model also introduces a “centerness” regression branch, sharing the same 4-layer convolution network as the classification branch. Its output is a float value, supposed to be:
\[q = \sqrt{\frac{\min(l,r)}{\max(l,r)} \times \frac{\min(t,b)}{\max(t,b)}} \in [0,1]\]Training and Inference
During training, the model outputs a vector of length $C+5$ for each input location, for the classification of $C$ classes, the centerness, and the 4 bounding box offset. The loss function used for training is:
\[L(p_{x,y}, q_{x,y}, t_{x,y}) = \frac{1}{N_{pos}} \sum_{x, y} \Big(L_{cls}(p_{x,y}, c^\ast_{x,y})+L_{ctr}(q_{x,y})\Big) + \frac{\lambda}{N_{pos}} \sum_{x, y} \mathbb{I}_{c^\ast_{x,y}>0} L_{reg}(t_{x,y}, t^\ast_{x,y})\]where $c^\ast$ is the ground truth class label, $p_{x,y}$ is the probability output of the predicted class label, $q_{x,y}$ is the centerness output, $t_{x,y}$ is the predicted bounding box offset, and those with an asterisk are the ground truth. $L_{cls}$ is the focal loss (cross-entropy with scaling factor to address imbalanced data), $L_{ctr}$ is the centerness loss (binary cross-entropy), and $L_{reg}$ is IoU loss (negative log IoU). Specifically,
\[\begin{aligned} L_{cls}(p_{x,y}, c^\ast_{x,y}) &= -\alpha_{x,y} (1-p_{x,y})^\gamma \log(p_{x,y}) \\ L_{ctr}(q_{x,y}) &= - \log(q_{x,y}) \\ I &= \big(\min(t,t^\ast) + \min(b,b^\ast)\big) \times \big(\min(l,l^\ast) + \min(r,r^\ast)\big) \\ U &= \big((t+b) \times (l+r)\big) + \big((t^\ast+b^\ast) \times (l^\ast+r^\ast)\big) - I \\ L_{reg}(t_{x,y}, t^\ast_{x,y}) &= - \log\frac{I}{U} \end{aligned}\]where $\gamma$ is the focal loss parameter to emphasize the hard samples with low predicted $p_{x,y}$ and $\alpha_{x,y}$ is the scaling factor to balance the positive/negative samples ($\alpha_{x,y}=\alpha$ for positive samples and $\alpha_{x,y}=1-\alpha$ for negative samples for a system-wide constant $\alpha$).
At inference, the classification score $p_{x,y}$ is multiplied with the centerness $q_{x,y}$ to allow the model to downweight the score of bounding boxes that are not centered at the object. Then the modified classification score is used for non-maximum suppression (NMS) to produce quality bounding boxes.
The model was trained using SGD for 90K iterations with batch size 16. Images are resized with shorter side 800 pixels and longer side less than 1333 pixels. The initial learning rate is 0.01, then reduce by a factor of 10 at iteration 60K and 80K. Weight decay and momentum are set to 1e-4 and 0.9, respectively.
Implementation
The author’s implementation is available at https://github.com/tianzhi0549/FCOS. Detectron2 also has one.
The FCOS config in Detectron2 is available as configs/common/models/fcos.py. It is based on the RetinaNet config (which also uses ResNet-50 as the backbone, $C_3,C_4,C_5$ as the backbone output, $P_3,P_4,P_5,P_6,P_7$ as the FPN, and defined focal loss with $\gamma=2$ and $\alpha=0.25$).
The result is a “model” object, which is instantiated from the class FCOS. Compare to the RetinaNet class (in detectron2/modeling/meta_arch/retinanet.py), anchor-related elements
(namely, anchor_generator, anchor_matcher, box2box_transform, and input_format)
are not accepted by the class constructor, hence they are removed at the config.
The prediction head of RetinaNet is also replaced with the FCOSHead class. These classes are defined in detectron2/modeling/meta_arch/fcos.py. The model created will be like this:
FCOS(
(backbone): FPN(
(fpn_lateral3): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_lateral4): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output4): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_lateral5): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(top_block): LastLevelP6P7(
(p6): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(p7): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
)
(bottom_up): ResNet(
(stem): BasicStem(
(conv1): Conv2d(
3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
)
(res2): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv1): Conv2d(
64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
)
(res3): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv1): Conv2d(
256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
)
(res4): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
(conv1): Conv2d(
512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(3): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(4): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(5): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1),
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
)
)
)
(head): FCOSHead(
(cls_subnet): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): GroupNorm(32, 256, eps=1e-05, affine=True)
(2): ReLU()
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): GroupNorm(32, 256, eps=1e-05, affine=True)
(5): ReLU()
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): GroupNorm(32, 256, eps=1e-05, affine=True)
(8): ReLU()
(9): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(10): GroupNorm(32, 256, eps=1e-05, affine=True)
(11): ReLU()
)
(bbox_subnet): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): GroupNorm(32, 256, eps=1e-05, affine=True)
(2): ReLU()
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): GroupNorm(32, 256, eps=1e-05, affine=True)
(5): ReLU()
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): GroupNorm(32, 256, eps=1e-05, affine=True)
(8): ReLU()
(9): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(10): GroupNorm(32, 256, eps=1e-05, affine=True)
(11): ReLU()
)
(cls_score): Conv2d(256, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bbox_pred): Conv2d(256, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(ctrness): Conv2d(256, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(anchor_generator): DefaultAnchorGenerator(
(cell_anchors): BufferList()
)
)
This object defined the forward functions for training and inference as well as the loss function. In the forward function, the input (images) will be preprocessed, then pass through the backbone and the prediction head. Then the images, the feature maps from backbone, and the prediction produced by the head are processed by the forward_training() function during training, or the forward_inference() function during inference.
The head class FCOSHead products a vector of logits, a vector of bounding box regression, and the centerness value. The model’s forward_training() function then process them to match with the ground truth and produce the loss metric.
The loss function returns loss of a dict of three components (loss_fcos_cls, loss_fcos_loc, loss_fcos_ctr) instead of a single value. But note that the exact computation of loss (such as the focal loss with parameters $\gamma$ and $\alpha$) is from fvcore. The overall loss used for backpropagation is the simple sum of the three components (i.e., $\lambda=1$ in the loss equation above).
The FCOS head code from Detectron2 is as follows:
class FCOSHead(RetinaNetHead):
"""
The head used in :paper:`fcos`. It adds an additional centerness
prediction branch on top of :class:`RetinaNetHead`.
"""
def __init__(self, *, input_shape: List[ShapeSpec], conv_dims: List[int], **kwargs):
super().__init__(input_shape=input_shape, conv_dims=conv_dims, num_anchors=1, **kwargs)
# Unlike original FCOS, we do not add an additional learnable scale layer
# because it's found to have no benefits after normalizing regression targets by stride.
self._num_features = len(input_shape)
self.ctrness = nn.Conv2d(conv_dims[-1], 1, kernel_size=3, stride=1, padding=1)
torch.nn.init.normal_(self.ctrness.weight, std=0.01)
torch.nn.init.constant_(self.ctrness.bias, 0)
def forward(self, features):
assert len(features) == self._num_features
logits = []
bbox_reg = []
ctrness = []
for feature in features:
logits.append(self.cls_score(self.cls_subnet(feature)))
bbox_feature = self.bbox_subnet(feature)
bbox_reg.append(self.bbox_pred(bbox_feature))
ctrness.append(self.ctrness(bbox_feature))
return logits, bbox_reg, ctrness
In which most of the function inherits from the RetinaNetHead class. The centerness prediction is implemented as a convolution layer. Also note that comment there: The learnable scale factor is not used because the bounding box regression target is not interpreted as multiples of the corresponding stride.
Bibliographic data
@inproceedings{
title = "FCOS: Fully Convolutional One-Stage Object Detection",
author = "Zhi Tian and Chunhua Shen and Hao Chen and Tong He",
booktitle = "In Proceedings of the IEEE International Conference on Computer Vision (ICCV)",
month = "Oct",
year = "2019",
pages = "2627--2636",
arXiv = "1904.01355",
code = "https://github.com/tianzhi0549/FCOS",
url = "https://openaccess.thecvf.com/content_ICCV_2019/papers/Tian_FCOS_Fully_Convolutional_One-Stage_Object_Detection_ICCV_2019_paper.pdf",
}