GPT-OSS is an open source, open weight model by OpenAI with Apache 2.0 license. It is an autoregressive mixture-of-experts (MoE) model that specialized in reasoning (chain of thought), tool use, and support structured output. Similar to Llama architecture, it uses pre-norm with RMS norm and each expert is a SwiGLU-based MLP.
The architecture of GPT-OSS is as follows:
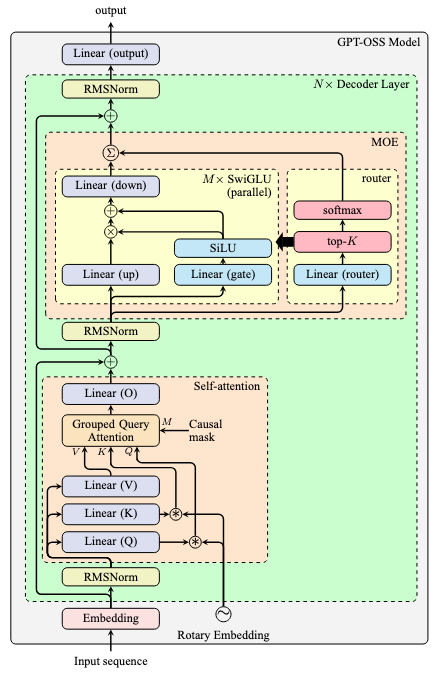
Some notable features include:
- RoPE is used with YaRN (Yet another RoPE extension, arXiv:2309.00071) for long context support
- In self-attention, the SDPA is used with learnable sink
- SwiGLU is with clamping and residual connection
There are two versions of GPT-OSS, namely 120B and 20B. Their parameters are as follows:
| Parameter | gpt-oss-120b | gpt-oss-20b |
|---|---|---|
| Model Size | 116.83B | 20.91B |
| Active parameters | 5.13B | 3.61B |
| MLP parameters | 114.71B | 19.12B |
| Attention parameters | 0.96B | 0.64B |
| Embed/Unembed params | 1.16B | 1.16B |
| Vocab Size | 201,088 | 201,088 |
| Embedding dimension | 2,880 | 2,880 |
| Context length | 131,072 | 131,072 |
| Decoder layers | 36 | 24 |
| Attention heads | 64 | 64 |
| Key-value heads | 8 | 8 |
| Attention dimension | 128 | 128 |
| SwiGLU per MOE layer | 128 | 32 |
| Intermediate dimension | 2,880 | 2,880 |
| Active experts per MOE layer | 4 | 4 |
Implementation details
Tokenizer used is o200k_harmony, open sourced BPE in tiktoken with 201,088 tokens. It is a successor of o200k_base. Some special tokens are defined (for the Harmony chat format) for the role-based prompting and multi-spearker transcripts.
import tiktoken
o200k_harmony = tiktoken.get_encoding("o200k_harmony")
Attention mechanism: SDPA with learnable sink (arXiv:2603.11487, see also the off-by-one attention). Essentially, it computes SDPA with the following formula:
\[\begin{aligned} \text{Attention}(Q,K,V) &= \text{softmax}_\beta\Big(\frac{QK^\top}{\sqrt{D}}\Big)V \\ \text{softmax}_\beta(x) &= \Big[\frac{\exp(x_i)}{\beta + \sum_j \exp(x_j)} \Big]_i \end{aligned}\]where $\beta$ is a learnable bias.
Attention with sink means the softmax is not required to produce a vector that sum to 1. In fact, the original design was to allow the softmax to be zero-valued, so that the attention can output zero after the weighted sum on $V$. The position that zero is produced is called the non-trigger position of the sequence.
The reason you want this is because multi-head attention is used. Some head may be specialized for certain tasks. If the situation should not activate that head, it is dormant. That head should better output zero in those cases.
Without sink, it was observed that the attention weight concentrates on the BOS special token — as a “parking” spot for non-trigger positions to mean no-op. BOS token is chosen not because it is the special token, but because of its position in the sequence is a convenient one. During training, the BOS token’s value will be shaped to be near-zero to fit the purpose as a sink (arXiv:2410.10781).
The implementation of SDPA with sink can be found in the following code from the official repository, comments added:
# compute QK^\top / \sqrt{d}
QK = torch.einsum("qhmd,khmd->hmqk", Q, K)
QK *= sm_scale
# apply mask
QK += mask[None, None, :, :]
# concat with sink along the dimension of sequence length of "K"
QK = torch.cat([QK, S], dim=-1)
# softmax along the dimension of sequence length of "K"
W = torch.softmax(QK, dim=-1)
# remove the sink - sum <= 1
W = W[..., :-1]
# weighted sum on V
attn = torch.einsum("hmqk,khmd->qhmd", W, V)
Dropout is not used. In fact, most models after GPT2 has no dropout since the models are trained for a single epoch (rather than multi-hundred epochs) over a massive dataset. All tokens are seen only once and there is no risk of overfitting. Pythia 1.4B confirms that dropout can only hurt the downstream performance.
MoE router is implmented as usual: linear + top-k + softmax:
g = gate_linear(x)
experts = torch.topk(g, k=k, dim=-1, sorted=True)
expert_indices = experts.indices
expert_weights = F.softmax(experts.values, dim=-1)
SwiGLU are used as experts, but with clamping and residual connection. A skeleton implementation is as follows (adapted from the official code):
gate_up = hidden_state @ gate_up_proj + gate_up_bias
gate, up = gate_up[..., ::2], gate_up[..., 1::2]
gate = gate.clamp(min=None, max=limit)
up = up.clamp(min=-limit, max=limit)
glu = gate * torch.sigmoid(gate * alpha)
gated_output = (up + 1) * glu
out = gated_output @ down_proj + down_bias
In the official code, even SwiGLU has three linear projections, the gate and up are combined into a single projection matrix to let you call matmul together. Then the projected gate part is upper-bounded by limit, and the up part is bounded between -limit and limit, where limit is a configuration parameter default to 7. The Swish function is implemented using sigmoid and multiplication (with alpha=1.702).
The conventional SwiGLU is:
\[\text{SwiGLU}(x) = (xW_2 + b_2) \otimes \sigma(\alpha (xW_1 + b_1))\]but GPT-OSS uses the following instead:
\[\text{SwiGLU}(x) = (xW_2 + b_2) \otimes \sigma(\alpha (xW_1 + b_1)) \oplus \sigma(\alpha (xW_1 + b_1))\]The extra $\oplus$ part is the “residual connection”, implemented using:
gated_output = (up + 1) * glu
Then the down projection is applied as usual.
Training and post-training
The model card did not mention the exact dataset for training. It only revealed that the pretraining used trillions of tokens from STEM, coding, and general knowledge domains. The total training time for the 120B model is 2.1M hours of H100, and 10x fewer for the 20B model.
While the model card said that Flash Attention is used for reduced memory requirements and accelerate training, the official code implemented the SDPA using primitive PyTorch operations.
Post-training is done with chain-of-thought (CoT) reinforcement learning (RL) technique as in OpenAI o3. The model is taught how to reason and solve problems using CoT and how to use tools. The dataset used for post-training includes coding, math, science, and more.
GPT-OSS is claimed to be a customizable model. Seems what it means is that you can prompt the model to reason in low/medium/high complexity levels, by inserting keywords such as “Reasoning: high” in the system prompt.
The most notable feature of GPT-OSS is its use of harmony chat format, which uses special tokens to delineate message boundaries and keyword arguments to indicate message authors and recipients. This is to make the model output in a structured way. It also uses a role-based information hierarchy to resolve instruction conflicts: System > Developer > User > Assistant > Tool.
Below is an example:
<|start|>system<|message|>You are ChatGPT, a large language model trained by OpenAI.
Knowledge cutoff: 2024-06
Current date: 2025-06-28
Reasoning: high
# Valid channels: analysis, commentary, final. Channel must be included for every message.
Calls to these tools must go to the commentary channel: 'functions'.<|end|>
<|start|>developer<|message|># Instructions
Always respond in riddles
# Tools
## functions
namespace functions {
// Gets the location of the user.
type get_location = () => any;
// Gets the current weather in the provided location.
type get_current_weather = (_: {
// The city and state, e.g. San Francisco, CA
location: string,
format?: "celsius" | "fahrenheit", // default: celsius
}) => any;
} // namespace functions<|end|><|start|>user<|message|>What is the weather like in SF?<|end|><|start|>assistant
where “channel” is to indicate the intended visibility, e.g., “analysis” for CoT and “commentary” for tool calling, “final” for that show to users. It is trained for agentic tool use, including search and interact with web, Python tool to run code, and arbitrary developer functions in Developer message.
The released model applied MXFP4 quantization on the MOE weights.
Bibliographic data
@unpublished{
title = "gpt-oss-120b & gpt-oss-20b Model Card",
author = "OpenAI",
year = "2025",
month = "Aug",
arxiv = "2508.10925",
}